[Oracle] Python DataFrame Insert 속도 문제 해결 (CLOB 자료형 문제)
2022. 1. 17. 23:15
반응형
현상
Python에서 to_sql() 메서드로 dataframe을 Oracle 데이터베이스에 Insert 할때
Dataframe 컬럼중 테이터타입이 object인 경우 CLOB(Character large object, CLOB) 자료형으로 매핑되어 Insert가 됨
(CLOB으로 Insert 되게 되면 속도가 매우 느립니다)
- CLOB : 대용량의 텍스트 데이터를 저장하기 위한 데이터 타입으로 최대 4GB 까지 저장가능
- BLOB : 대용량의 바이너리 데이터를 저장하기 위한 데이터 타입으로 최대 4GB
- BFILE : 대용량의 바이너리 데이터를 파일 형태로 저장하기 위한 데이터 타입 최대 4GB
- 참고 : https://sksstar.tistory.com/72
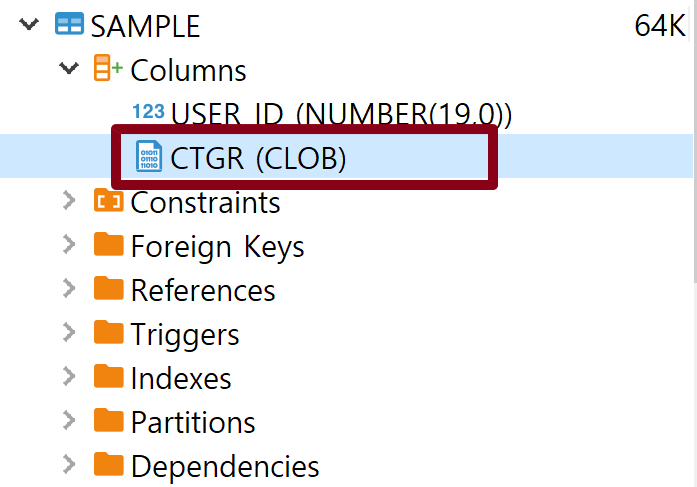
문제점
- CLOB 자료형으로 Insert 할 경우 속도가 매우느림
- CLOB데이터는 사용하기 불편함
- CLOB 형태로 저장할 필요가 없는 데이터인데 굳이 느린 속도로 불편하게 사용할필요가 없음
해결 방법
- dataframe의 컬럼 중 데이터타입이 object인 경우 clob이 아닌 varchar로 Insert 되도록 매핑
- 상세코드 아래 첨부
import numpy as np
import pandas as pd
import sqlalchemy as sa
from sqlalchemy import create_engine
engine = create_engine('oracle://{}:{}@{}'.format(USERNAME, PASSWORD, DATABASE))
df = pd.read_csv("file_path")
# object 타입 추출 및 매핑
object_columns = [c for c in df.columns[df.dtypes == 'object'].tolist()]
dtyp = {c:sa.types.VARCHAR(df[c].str.len().max()) for c in object_columns}
df.to_sql(name="", schema="", con=engine, if_exists="", ..., dtype=dtyp)
참고 자료
https://stackoverflow.com/questions/42727990/speed-up-to-sql-when-writing-pandas-dataframe-to-oracle-database-using-sqlalch
반응형
'컴퓨터 기본 > 데이터베이스(DB)' 카테고리의 다른 글
| [데이터베이스] 데이터 테이블 종류 및 특성 (운영계 - OLTP 관점) (1) | 2022.03.22 |
|---|---|
| [Oracle] Distinct(unique) 누적 유저 수 구하기 예제 쿼리 (0) | 2022.01.26 |
| [DB 튜닝] DB 튜닝 개론 / 기초 (0) | 2021.12.06 |
| [Oracle] 날짜 표시 형식 변경하기 (시분초까지 보이게하기) (0) | 2021.06.19 |
| [DB] 쿼리 조건문 WHERE 1=1, WHERE 절에 1=1 사용 하는 이유 (동적 쿼리) (1) | 2021.06.05 |