[정보] 하둡(Hadoop) ? 하둡에코시스템 ? 무엇이죠?
# 하둡(Hadoop) = 하둡에코시스템(Hadoop-Ecosystem)
대용량데이터 저장, 분석과 이를 활용한 인공지능(AI)이 화두가 되고 있는 요즘 하둡, 하둡에코시스템 2가지 용어가 자주 보입니다. 저희가 일반적으로 이야기하는 하둡은, 하둡에코시스템(이하 하둡)을 줄여서하는 말이라고 보시면 되겠습니다.
# 2019-11-16 내용 일부 보충
일반적으로 업무상에서 언급하면 사람들은 하둡에코시스템을 생각합니다.
하둡에코시스템에 포함되는 Pig, Hive, ZooKeeper 등을 따로 두고 하둡을 사용하는 것을 생각할 수 없기 때문이죠.
하지만 엄밀히 보았을 때 하둡은 분산 저장/분산처리를 지원하는 아래 2가지를 의미합니다.
- 분산 저장 파일 시스템 : HDFS(Hadoop Distributed File System)
- 분산 처리 시스템 Map Reduce
위의 2가지는 2003년 논문으로 발표된 구글 파일 시스템 (GFS, Google File System)의 오픈소스 버전이라고 보면 되겠습니다.
혹시 오해가 있을까 내용 보충했으니 참고해주시면 감사하겠습니다.
# 하둡(Hadoop)이란 ?
하둡은 분산 방식으로 빅데이터 저장/처리를 용이하게 해주는 자바(Java)기반 오픈소스 프레임워크입니다.
분산 방식은 데이터의 분산 저장(HDFS, Hadoop Distributed File System 기반), 분산처리(MapReduce 기반) 2가지 모두를 지원하고, 오픈소스 이기에 무료로 사용할 수 있습니다.
하둡의 기능은 크게 수집, 저장, 처리, 관리 4가지가 있고 각각을 지원하는 여러 가지 프로그램들이 있습니다.
4가지 기능을 간단히 표로 보면 아래와 같고
아래의 프로그램을 묶음으로 제공하는 배포판을 설치하면 모든 기능을 쉽게 사용할 수 있습니다.
| 기능 | 설명 |
| 수집 | 데이터의 수집 : 플럼(Flume), 스쿱(Sqoop) 등 |
| 저장 | 데이터의 저장 : Hbase |
| 처리 | 데이터의 처리 : 하이브(Hive), 피그(Pig), 마후트(Mahout) |
| 관리 | 데이터의 관리 : 우지(Oozie), Hcatalog, 주키퍼(Zookeeper) |
각각의 기능을 지원하는 프로그램의 이름을 보면 동물 이름에서 유래된 것이 많고, 따라서 관리 프로그램의 이름도 주키퍼(Zookeeper)인 것을 볼 수 있습니다.
추가적으로 하둡에코시스템의 구성을 잘 설명하는 그림이 있어 아래에 첨부합니다.
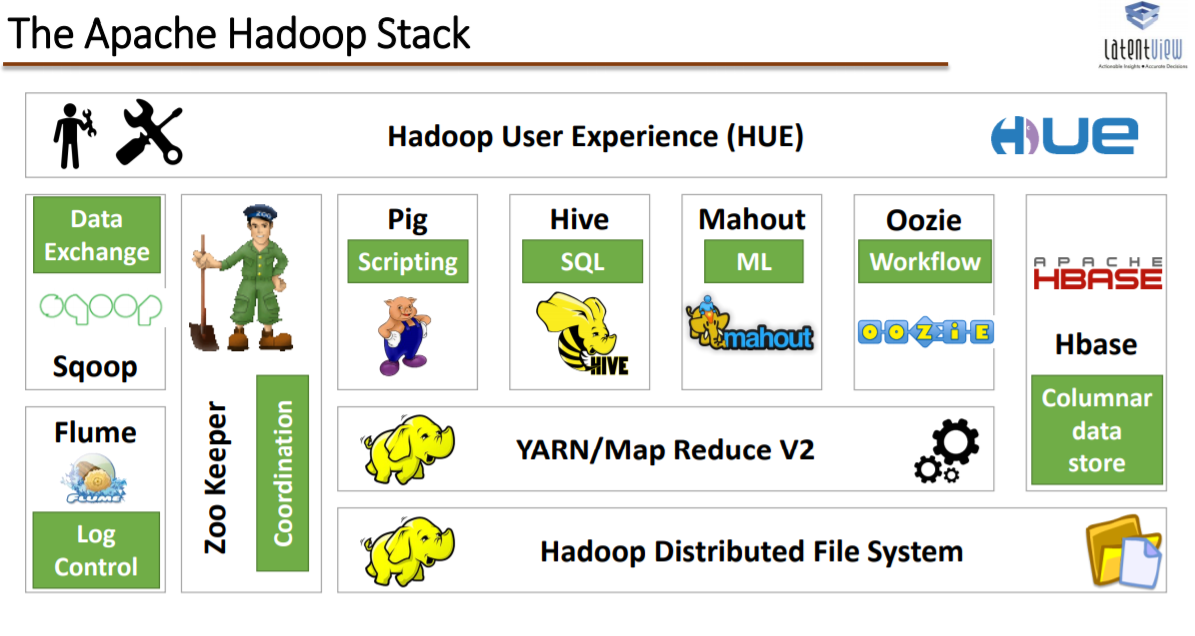
위의 그림을 좌측부터 보시면 수집을 위한 Sqoop, Flume이 보이고 차례대로 관리를 위한 Zoo Keeper, 데이터 처리를 위한 Pig, HIve, Mahout, Oozie(관리로 보기도)와 데이터 저장을 위한 Hbase 등을 볼 수 있습니다.
제일 위에 보이는 HUE(Haddop User Experience)는 하둡의 여러 구성요소를 통합으로 다룰 수 있는 사용자 인터페이스입니다. HUE를 사용하면 하둡의 여러 기능들을 쉽게 사용할 수 있습니다.
참고 :
1. https://www.youtube.com/watch?v=_d-wNMxIn8U
2. https://www.slideshare.net/rohitkulky/scaling-up-with-hadoop-and-banyan-itrix-feb-2015-public-copy